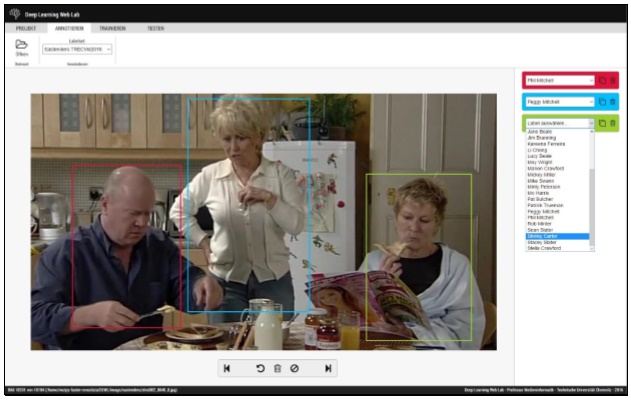
Webinterface für Annotation [Quelle: S. Kahl: Präsentation TUC at TrecVid 2016
Ziel war die Verbesserung der Vorjahres-Ergebnisse unter Nutzung von Open Source Tools auf Consumer Hardware. Dabei sollten vor allem speziell entwickelte Annotationswerkzeuge zur kollaborativen Nutzung über ein Webinterface zum Einsatz kommen mit denen mehr Ground-Truth Daten pro Zeiteinheit erzeugt werden können. Außerdem wurden Zeiten erfasst um u.a. die effizientesten Nutzer für den interaktiven Run zu bestimmen. Daten-Grundlage des Wettbewerbs war auch dieses Mal wieder die britische TV-Serie “Eastenders”. Im Wettbewerb galt es bestimmte Rollen der Serie an einem definierten Ort automatisiert zu ermitteln. Dazu erfolgte im ersten Schritt nach der Extraktion der sog. Keyframes deren Annotation durch Markieren von Personen mit Bounding Boxen (mittels Rechtecken, siehe Abbildung) und Metadatenanreicherung mit Ortsinformationen. Zur Personen- und Ortsklassifikation wurden dann im zweiten Schritt neuronale Netze (CNNs — Convolutional Neural Networks) trainiert. Da aufeinanderfolgende Bilder am selben Ort mit großer Wahrscheinlichkeit zu einer Szene (Shot) gehören, wurden Ähnlichkeitsmetriken angwandt, um Bilder einem Shot und damit einer Gruppennummer zuzuordnen. Schritt drei beinhaltete ein Re-Ranking der Ergebnisse der CNNs durch Mittelung der CNN-Konfidenzwerte aller Bilder einer Gruppe. Schließlich folgte im interaktiven Run die manuelle Evaluation der Ergebnisse mit Hilfe des Webinterfaces durch den zeiteffizientesten Annotator.
Die Forscher erzielten mit ihrer Methode eine durchschnittliche Trefferquote von 31,8% im Interactive Run und 14,4% im Automatic Run, wobei die Top 10 Präzision 90,5% (IR) und 49,7% (AR) betrug. Damit erreichte die TU Chemnitz den 2. Platz im Interactive Run und den 5. Platz im Automatic Run.
![Standbild des Laserschweißprozesses mit modellierter Ellipse [aus: Kowerko, Danny; Ritter, Marc; Manthey, Robert; John, Björn & Grimm, Michael: Quanti?zierung der geometrischen Eigenschaften von Schmelzzonen bei Laserschweißprozessen]](https://localize-it.de/files/2016/10/laserschweißen-e1476797349473.png)
![Überblick von Ähnlichkeitsmaßen bewertet von Mensch und Maschine [aus: Ritter et al: Simplifying Accessibility Without Data Loss: An Exploratory Study on Object Preserving Keyframe Culling, S.9]](https://localize-it.de/files/2016/06/HCII_bild_2.jpg)
![Frequenzspektren von Sprach- sowie nicht-Sprachereignissen [aus: Hussein et al: Acoustic Event Classification for Ambient Assisted Living and Health Environments]](https://localize-it.de/files/2016/08/paper.png)





